
A clinic manager in Fort Worth exports patient forms to a shared drive because it's quick. A law office in Dallas stores intake documents in email folders because that's how the team has always worked. A growing accounting firm keeps payroll files, proposals, and marketing drafts in the same cloud repository with broad staff access because nobody has had time to sort it out.
That's the normal starting point for many small and mid-sized businesses. Data exists everywhere, staff members are busy, and “we'll clean it up later” turns into a permanent operating model.
A data classification policy fixes that mess without turning the business into a bureaucracy. It gives the company a simple rulebook for what data it has, how sensitive that data is, who gets access, and what controls belong around it. For regulated SMBs in DFW, that isn't a luxury. It's a practical way to avoid confusion, tighten operations, and make compliance work less painful.
Businesses that deal with medical records, legal files, payment data, donor information, project documents, or employee records don't need a giant enterprise program to get this right. They need a usable framework, clear ownership, and a checklist that fits a real budget.
Table of Contents
- Your First Step in Data Protection
- Why a Data Policy Is Non-Negotiable Today
- Understanding Data Classification Levels
- Building Your Policy and Governance Framework
- Implementing and Enforcing Your Policy
- A Practical Implementation Checklist for SMBs
- Common Pitfalls for SMBs and How to Avoid Them
- How Technovation Delivers Stress-Free Compliance
Your First Step in Data Protection
A small business owner usually doesn't wake up thinking about classification labels. The day is full of payroll, customers, staffing, invoices, and whatever fire showed up overnight. Data handling becomes informal because informal feels efficient.
Then the cracks start showing. A staff member sends the wrong attachment. A former employee still has access to internal folders. A client asks how sensitive records are protected, and nobody can answer with confidence. The business isn't reckless. It's operating without a shared system.
That's why a data classification policy matters so early. It creates order before the business is forced to create order during an audit, client dispute, or security incident. For a healthcare practice, that may mean separating general patient education content from protected records. For a law firm, it may mean distinguishing public court filings from privileged client strategy. For a nonprofit, it may mean keeping donor data away from broad volunteer access.
Practical rule: If staff members have to guess how a file should be stored, shared, or protected, the business already needs a data classification policy.
This doesn't have to start with a massive documentation project. A business can begin with a shortlist of common data types, assign simple sensitivity levels, and tell employees what each level requires. That alone reduces confusion fast.
Healthcare organizations that want a deeper view into sensitive information handling can also benefit from a complete guide for healthcare data engineers, especially when privacy and de-identification questions overlap with classification decisions.
The point is simple. Classification is not an enterprise-only exercise. It's the first clean step toward control.
Why a Data Policy Is Non-Negotiable Today
The old excuse was that formal data handling could wait until the company got bigger. That no longer works. Small and mid-sized businesses operate in the same regulatory environment, face the same client expectations, and rely on the same digital systems as larger firms. The difference is that SMBs usually have less margin for error.
Risk gets smaller when sensitivity gets clear
Most security problems around data don't start with advanced attacks. They start with ordinary mistakes. Files are stored in the wrong place. Permissions are too broad. Staff share documents through convenience instead of policy.
A data classification policy reduces that chaos because it forces one basic decision first: what kind of data is this? Once that answer is clear, the business can apply the right access rules, retention standards, and safeguards. Sensitive data gets tighter controls. Public material doesn't waste security effort.
That's why classification is a business control, not just an IT task. It reduces accidental exposure and protects the information that matters.
Compliance starts with classification
For regulated businesses, this isn't optional. Regulatory frameworks such as GDPR, CCPA, HIPAA, and PCI explicitly mandate that organizations perform data classification to prove compliance, requiring policies to include measurable Key Performance Indicators (KPIs) and specific handling protocols for disposal, storage, and transfer based on sensitivity levels according to Satori's explanation of data classification requirements.
That matters because regulators and clients don't just want promises. They want evidence that the company knows what data it holds and how it treats that data. A firm that can't classify its information usually can't prove proper access control, secure transfer, or defensible disposal either.
Risk planning ties directly into this. Businesses that haven't mapped data sensitivity usually struggle to prioritize controls, which is why a stronger risk mitigation strategy belongs alongside classification work.
A company can't protect all data equally. It shouldn't try. It should protect data according to business impact and regulatory exposure.
Overspending usually starts with poor labeling
Many SMBs spend money in the wrong places because they don't distinguish routine business data from highly sensitive data. They lock down low-risk files with unnecessary friction, while high-risk records sit in ordinary workflows.
A better policy changes that. Marketing collateral can remain easy to distribute. Internal procedures can stay accessible to staff. Financial records, legal files, patient information, and privileged materials can receive stricter controls where they belong.
That creates two business outcomes owners care about. The company lowers unnecessary operational drag, and it spends security dollars where those dollars reduce risk.
Understanding Data Classification Levels
Most businesses overcomplicate this topic. The model is simpler than it sounds. Think of incoming mail in four piles. Some pieces can be posted on the front desk for anyone to read. Some belong inside the company only. Some require careful handling. Some should be opened by a tiny number of people and locked away afterward.
That is the core logic of a data classification policy.
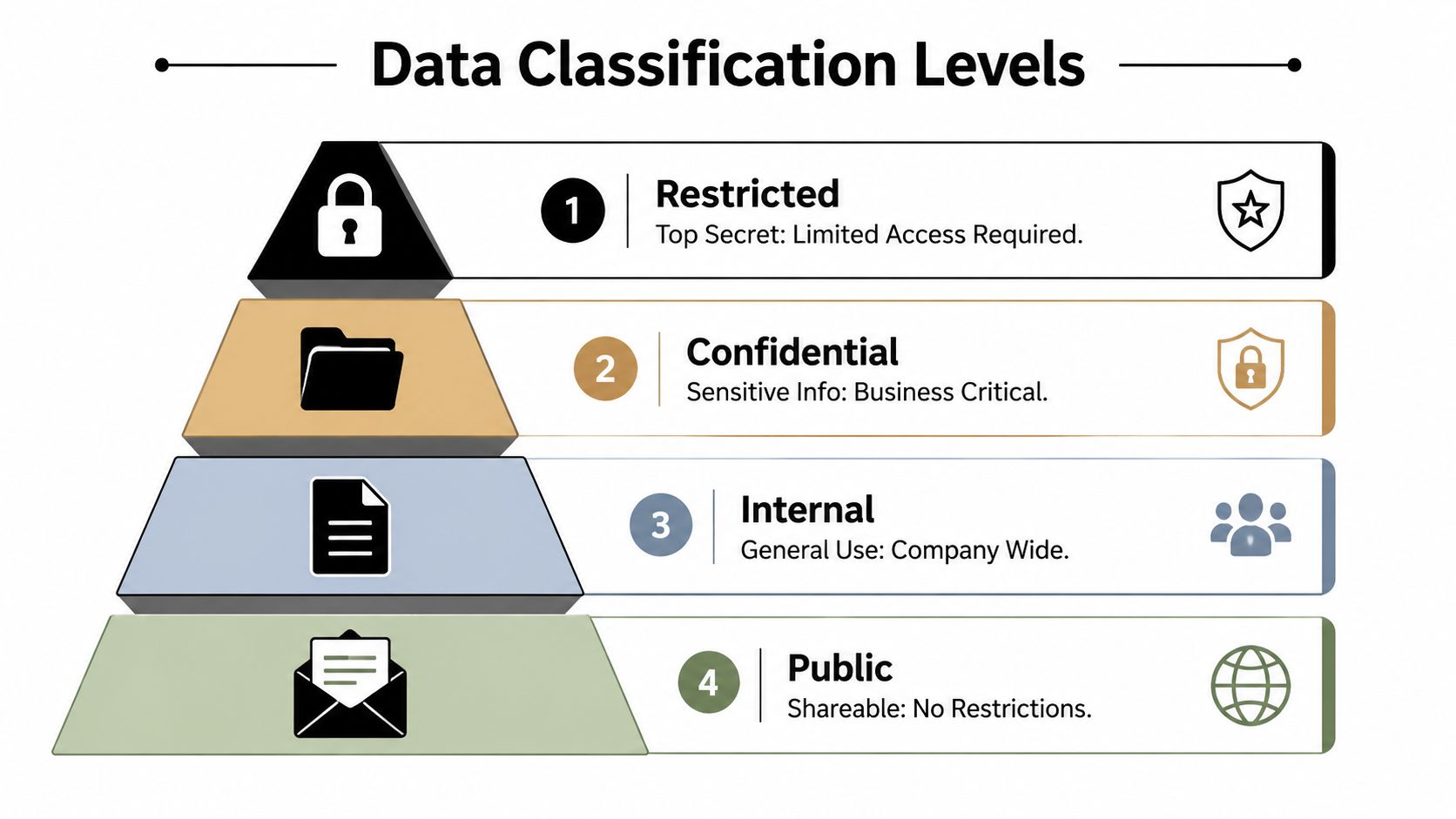
A data classification policy is a formal guideline that categorizes organizational data into four distinct security levels, Public, Internal, Confidential, and Restricted/Highly Confidential, to ensure sensitive information is handled according to its risk profile, as recommended by the National Institute of Standards and Technology (NIST) according to Securiti's overview of classification policy structure.
Here is the hierarchy in a format that can be quickly grasped.
A simple way to think about the four levels
Public data is safe to share outside the company. This includes website copy, approved brochures, job postings, or public-facing service descriptions. If disclosure causes no meaningful harm, it belongs here.
Internal data stays inside the business but usually doesn't require heavy restrictions. Staff directories, internal training guides, standard operating procedures, and ordinary meeting notes often fit this level. Employees may use it broadly, but it shouldn't be posted publicly.
Confidential data can harm the business, its clients, or its staff if exposed. This data type is often the primary focus for many regulated SMBs. Examples include employee files, client contracts, financial statements, patient records, case files, and sensitive project documents.
Restricted or Highly Confidential data is the smallest and most protected category. Access should be tightly limited on a strict need-to-know basis. This includes merger documents, legal strategy, credentials tied to critical systems, highly sensitive regulated records, and documents that could create severe legal or operational damage if disclosed.
A useful outside reference is this cybersecurity data classification guide, which helps teams compare practical labeling approaches without getting lost in theory.
Data Classification Levels at a Glance
| Level | Description | Examples for SMBs | Required Controls |
|---|---|---|---|
| Public | Safe for external sharing | Website content, public brochures, recruiting materials | Basic integrity control, approved publishing process |
| Internal | For employees and approved contractors only | Training manuals, internal workflows, meeting notes | Staff-only access, standard account permissions |
| Confidential | Sensitive business or regulated data | HR records, customer files, financial reports, patient charts, legal matters | Role-based access, secure storage, controlled sharing, stronger monitoring |
| Restricted | Highest sensitivity and highest impact if exposed | Executive strategy, privileged legal files, critical credentials, highly sensitive regulated records | Strict need-to-know access, strong encryption, approval-based sharing, enhanced logging |
Most SMBs don't fail because they chose the wrong label. They fail because they never defined labels at all.
A business doesn't need endless subcategories on day one. Four clear levels are enough to start making smarter decisions.
Building Your Policy and Governance Framework
Once the levels are defined, the business needs an actual document and assigned ownership. Without that, classification stays theoretical. The strongest policies are short, plain-language, and specific about responsibility.

What the policy document must include
A practical policy for an SMB should include these core sections:
- Purpose: State why the company classifies data and what business problem the policy solves.
- Scope: Identify which systems, records, departments, devices, and storage locations fall under the policy.
- Classification levels: Define Public, Internal, Confidential, and Restricted in plain English.
- Handling rules: Explain how each level must be stored, shared, transferred, retained, and disposed of.
- Access standards: Tie data sensitivity to role-based access.
- Exceptions: Define who can approve deviations and how they're documented.
- Review cycle: Set a review schedule and trigger updates when business or regulatory conditions change.
A policy also needs supporting governance. Annual policy review is a mandatory best practice, and an effective policy must explicitly define roles and responsibilities for Data Owners, who are accountable for managing classification and granting access. This ensures accountability and that every employee knows the security protocols required, as explained in Hyperproof's guidance on data classification policy design.
That annual review matters more than many owners realize. Regulations shift. Teams change. New software gets deployed. Acquisitions, cloud migrations, and vendor relationships all alter where data lives and who touches it.
Who owns what inside a small business
A smaller company doesn't need a giant governance committee. It does need clear role definitions.
- Data Owner: Usually a department head or business leader. This person decides how data should be classified and who should access it.
- Data Custodian: Usually IT or an outside managed service provider. This role implements the controls the owner requires.
- Data User: Employees, contractors, and approved partners who handle the data according to policy.
A healthcare office manager may act as the Data Owner for patient scheduling records. A managing partner may own legal case files. A controller may own payroll and financial records. The custodian then configures permissions, backup handling, and protection measures to match those decisions.
Governance insight: If nobody owns a dataset, everyone assumes someone else does. That's how sensitive data ends up unmanaged.
Businesses that want a stronger legal and operational foundation should also define handling expectations in contracts and internal standards, including a clear data protection clause where appropriate.
The best governance model is not the fanciest one. It's the one employees can follow without confusion.
Implementing and Enforcing Your Policy
A written policy that nobody follows is decoration. Enforcement comes from two places working together. First, people need repeatable processes. Second, systems need technical rules that back those processes up.
Process controls that people can actually follow
Most SMBs make one common mistake. They publish a policy file, email it once, and call the project finished. That doesn't work. Staff need to see the policy inside day-to-day actions.
That means building classification into:
- Onboarding: New hires should learn the classification levels, common examples, and sharing rules before they gain broad system access.
- File creation: Templates, document naming standards, and intake procedures should include sensitivity labels where appropriate.
- Department workflows: HR, accounting, legal, healthcare, operations, and leadership teams should have simple examples tied to their work.
- Offboarding: Access to Internal, Confidential, and Restricted data should be revoked promptly and consistently.
Training should be specific, not abstract. Staff don't need a lecture on governance theory. They need to know whether a spreadsheet can be emailed, stored in a shared folder, or printed for a meeting.
Technical controls that make the policy stick
Manual classification alone creates too many mistakes, especially once data spreads across email, file systems, cloud apps, endpoint devices, and backups. Stronger programs use automation to apply and enforce labels consistently.
Automated, rule-based tagging can reduce manual error by up to 75% and enables security teams to respond to anomalies 3x faster than with manual reviews, significantly lowering breach risk by ensuring sensitive data is never mis-stored on unauthorized devices according to TrustCloud's analysis of rule-based classification enforcement.
That matters because most employees aren't trying to break policy. They're trying to get work done fast. Automation catches what busy humans miss.
A practical enforcement stack for an SMB usually includes:
- Role-based access: Sensitive folders, applications, and records should open only to approved roles.
- Automated tagging: Files and records should inherit labels based on content, source, location, or department workflow.
- Secure sharing controls: Confidential and Restricted information should have stricter external sharing rules.
- Monitoring and alerts: Access anomalies, unusual downloads, and policy violations should trigger review.
- Identity controls: Access should follow job role changes, new hires, and terminations without delay.
For teams that maintain internal technical content, this practical guide for securing developer documentation is useful because documentation often contains far more sensitive operational detail than leaders realize.
Identity discipline is what turns access rules into reality. Businesses that haven't tightened account lifecycle control usually struggle to enforce classification consistently, which is why identity management services belong in the same conversation.
The businesses that enforce policy well don't rely on memory. They build a system that makes the right action the easy action.
A Practical Implementation Checklist for SMBs
The project feels heavy until it's broken into a short sequence. Most SMBs can make solid progress by treating classification as an operational cleanup effort, not a giant transformation program.
The checklist
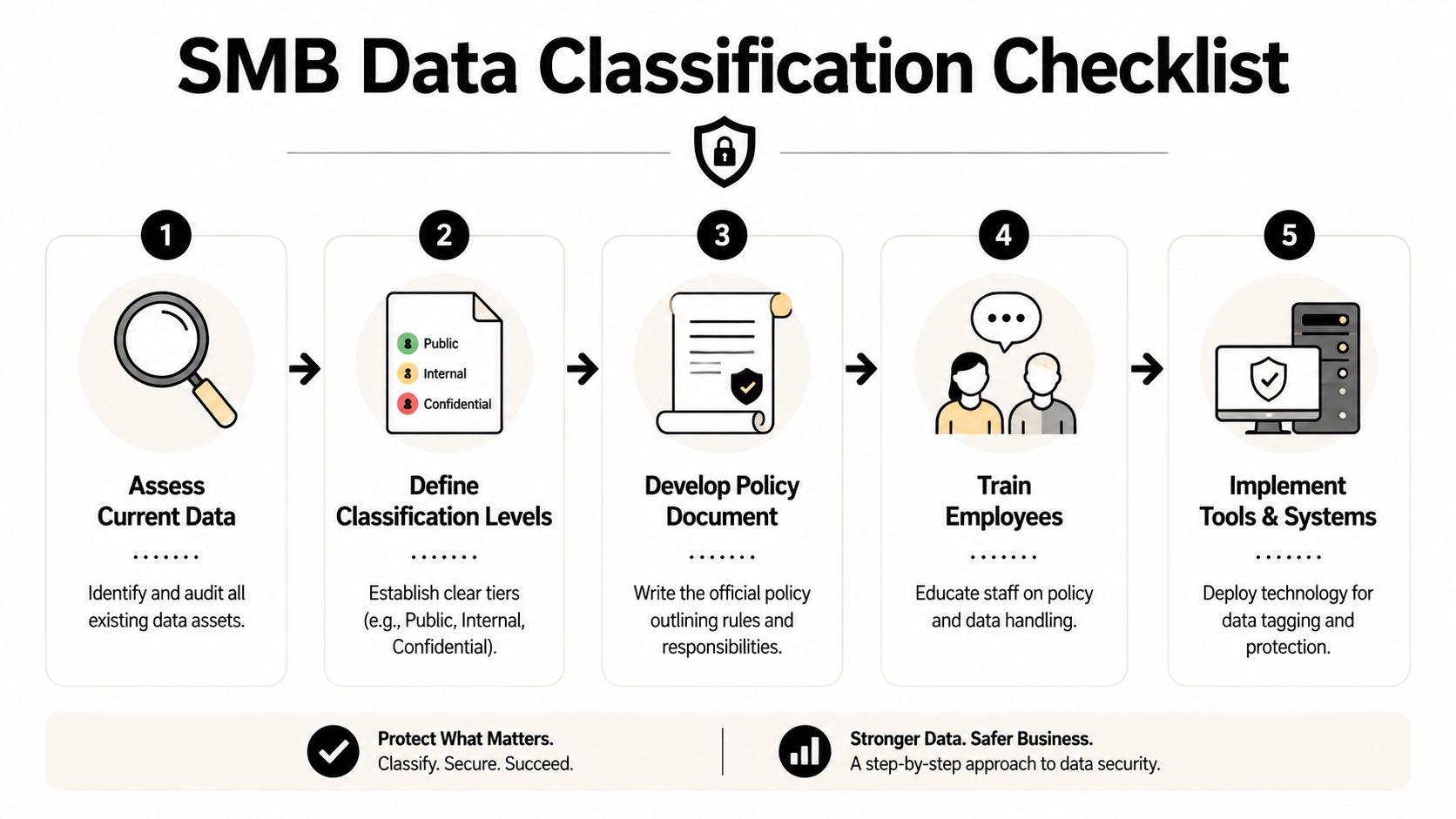
Get management buy-in
Leadership should approve the project, name an owner, and make it clear that departments must participate. Classification fails when it's treated as an IT side task.Build a basic data inventory
Identify what data the business holds and where it lives. Include on-premises systems, cloud repositories, employee devices, shared mailboxes, and backup locations.Choose the classification levels
Keep the model simple. Public, Internal, Confidential, and Restricted are enough for most SMBs in regulated sectors.Map common data types to each level
Don't leave staff guessing. Assign real examples such as client intake forms, invoices, HR records, donor lists, engineering drawings, or patient information.Draft the policy
Write short definitions, handling rules, ownership assignments, and approval paths. If the document is bloated, employees won't use it.Set permissions to match labels
Align folder access, application roles, and sharing permissions with classification decisions. At this point, policy starts affecting risk in a visible way.Add automation where it counts
Start with the highest-risk areas. Sensitive records should get tagging, access controls, and monitoring before lower-risk content does.Train employees by department
A receptionist, a paralegal, a project manager, and a bookkeeper don't handle the same data. Training should match the work.Back up sensitive data properly
Recovery planning matters just as much as classification. Businesses that classify critical data should also make sure that data is recoverable through dependable cloud backup solutions for small business.Review and adjust
Run a periodic check for mislabeled data, broken permissions, and new data types. A policy that isn't maintained will drift out of relevance.
The fastest way to stall this project is to aim for perfection. The better move is to classify the most important data first and expand from there.
A short, usable checklist beats a polished binder that never changes behavior.
Common Pitfalls for SMBs and How to Avoid Them
Most failed classification efforts don't fail because the concept is wrong. They fail because the business either overengineers the solution or ignores a newer risk that changed the sensitivity picture.
Cheap doesn't mean careless
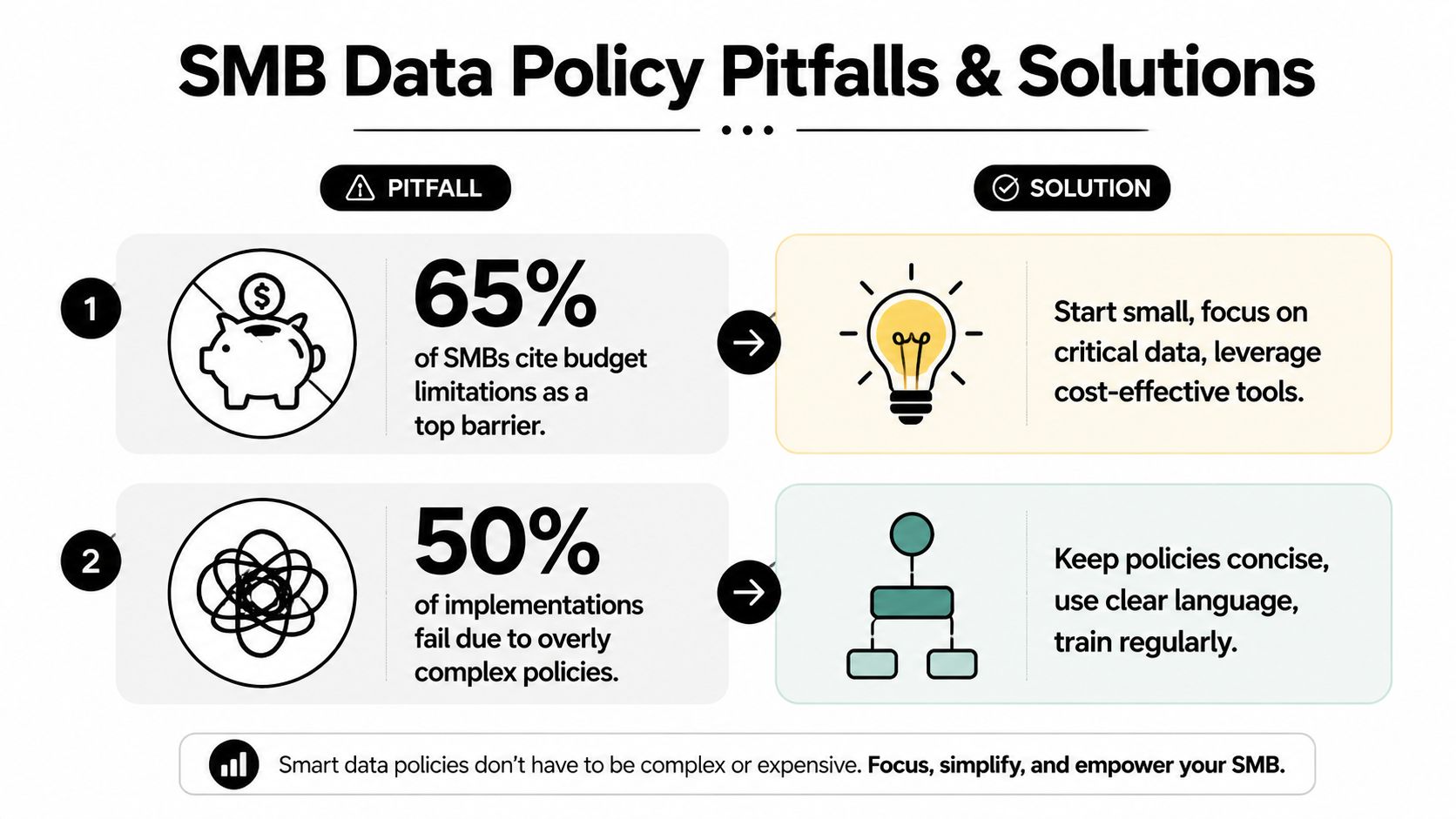
Plenty of SMBs assume classification requires enterprise-grade spending. That assumption pushes teams into one of two bad decisions. They either postpone the project indefinitely, or they build a bloated policy that nobody can enforce.
A better approach is narrower and cheaper. Start with the regulated and business-critical datasets first. Apply clear labels. Use rule-based workflows where possible. Keep the written policy short enough that a department manager can read it in one sitting and explain it to the team.
Low-cost execution usually means:
- Focusing on priority data first: Patient data, payment data, legal files, HR records, donor information, and executive documents come before general content.
- Using simple triggers: Folder location, document type, source system, and role can drive useful labeling decisions.
- Avoiding category sprawl: Too many labels create hesitation and misclassification.
- Reviewing a sample regularly: Small audits catch confusion before confusion becomes routine.
The biggest budget mistake isn't underbuying. It's paying for complexity the business can't operate.
AI changes sensitivity faster than most policies do
This is the gap many SMBs haven't noticed yet. A file may start as low-risk source material, but an AI workflow can combine or infer details that make the output far more sensitive than the input.
While 78% of SMBs now use AI tools, only 12% of data classification policies explicitly address how AI models alter data sensitivity. This is a critical gap, as 64% of data breaches in 2025 stemmed from misclassified AI-inferred data.
That changes the policy question. It's no longer enough to classify only the original file. Businesses also need rules for AI-generated summaries, extracted entities, inferred patterns, and combined outputs.
A sensible SMB response includes:
- Defining reclassification triggers: If AI generates new insights from regulated or sensitive inputs, the output should be reviewed and labeled accordingly.
- Restricting AI access to high-risk data: Not every system or workflow should have access to Confidential or Restricted material.
- Logging AI-driven data movement: If data is transformed, exported, or summarized, that action needs visibility.
- Training staff on derived sensitivity: Employees often assume summaries are safer than source files. That assumption can be dangerously wrong.
A policy that ignores AI-generated and AI-inferred data is already behind the way many businesses now work.
For DFW SMBs, especially in healthcare, finance, legal, and construction, the smartest policy is the one that stays simple while acknowledging that modern data doesn't always stay in the same risk category.
How Technovation Delivers Stress-Free Compliance
Most business owners don't struggle because the idea of a data classification policy is confusing. They struggle because the work touches too many moving parts at once. There are regulations to satisfy, permissions to clean up, devices to manage, backups to verify, employees to train, and ongoing monitoring to maintain.
That's where outside support changes the outcome. A managed partner can turn classification from a one-time document project into an operational system. That means helping the business inventory data, define sensible categories, align access rules, support identity controls, improve backup posture, and maintain review cycles that keep the policy current.
For regulated SMBs in Dallas-Fort Worth, that kind of support matters because local businesses usually need practical execution, not theory. They need a program that fits their size, their risk profile, and their budget. A medical office doesn't need enterprise theater. A law firm doesn't need more policy binders collecting dust. A construction company doesn't need a compliance project that slows every field operation. They need clarity, control, and follow-through.
Technovation LLC is built for that reality. The firm supports North Texas organizations with cybersecurity, compliance, managed IT, monitoring, backup, and strategic guidance that help businesses tighten data handling without overbuilding the solution. That's especially valuable for companies that know they need stronger controls but don't have time to design and maintain the full framework internally.
A good partner also prevents the common DIY mistake of fixing one layer while ignoring the others. Classification without identity governance is weak. Classification without backup discipline is incomplete. Classification without monitoring becomes stale. What works is a connected approach.
The right next step isn't guessing. It's getting a clear view of what data exists, where the exposure sits, and what can be improved first.
Technovation LLC helps DFW businesses turn data classification, compliance, backup, identity control, and day-to-day cybersecurity into a manageable system instead of a constant drain on staff time. For organizations that want practical answers without enterprise bloat, Technovation LLC offers a straightforward path forward, including a free security audit to identify gaps, reduce risk, and build a policy framework that fits the business.





